SHA-256 Usage in ZoKrates

The ZoKrates standard library exposes multiple families of interfaces for SHA-256 tailored for different scenarios:
- Compression only:
sha256,256bit,512bit,1024bit,1536bit - Fixed Size Padding + Compression:
256bitPadded,512bitPadded,1024bitPadded - Variable Size Padding:
sha256Padded
We are going to explain their differences, how to use them, and clarify which uses cases would be suitable for each. By the end of the guide you will form a solid understanding of how to use SHA-256 in your ZoKrates programs.
1. SHA-256 Overview
The SHA-256 hashing algorithm operates on blocks of input of size
512 bits per block and produces a fixed size 256 bits output.
To support inputs of arbitrary lengths (maximum 2^64 - 1), the SHA-256 specification describes a
padding procedure that expands inputs into the correct length - i.e., a
multiple of 512-bits.
Note that this padding procedure is applied even if the input size is already a
multiple of the block size.
After padding comes the so-called compression step that that applies the actual
SHA-256 hash computation.
Thus, a full SHA-256 execution involves a padding step, followed by the
compression step of all blocks.
The following diagram visualizes this notion.
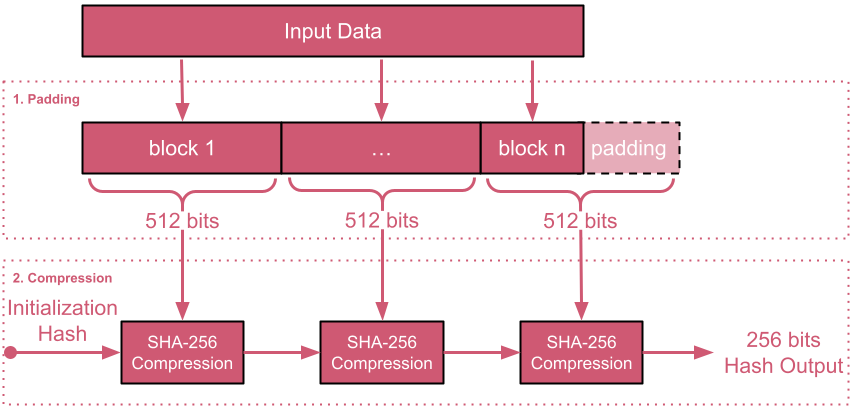
It is worth nothing that during the compression of a block ,the 512-bit block is treated as a set of 16 32-bit integers, where the hashing operations are applied onto those integers - referred to as the word size. Having this mind is important for understanding the SHA-256 interfaces ZoKrates provides.
2. SHA-256 in ZoKrates
At the core of the ZoKrates SHA-256 library is
sha256.zok
which implements the SHA-256 compression step, i.e., it assumes the input has
already been padded according to the SHA-256 specification, and only executes
the compression logic to produce a 256-bit hash.
Hence, this function takes an array of u32[16] integers, i.e.,
input data of size that is a multiple of the SHA-256 block size (N * 512 bits):
// sha256.zok
def main<N>(u32[N][16] a) -> u32[8] {
// SHA-256 compression logic
}
It should be clear now why the function accepts an input of this format: 16x32 = 512 bits is the block size, and 32-bit integers is the word size of SHA-256.
On top of sha256.zok there are multiple convenience interfaces.
These are explained next.
Compression Only Family
As explained, the core sha256.zok executes the compression step of SHA-256
over already padded inputs.
The library provides several wrappers with fixed-size
inputs:
512bit.zok: 512-bit inputs (64 bytes)1024bit.zok: 1024-bit inputs (128 bytes)1536bit.zok: 1536-bit inputs (192 bytes)
Like the core compression function, these provide compression-only over already padded data, i.e, the size of the already padded data equals exactly one of those sizes.
// Example: SHA-256 compression only for fixed size 512 bits inputs
import "hashes/sha256/512bit" as sha256Compression512bit;
def main(u32[8] chunk1, u32[8] chunk2) -> u32[8] {
// SHA-256 compression for 512bit pre-padded input
return sha256Compression512bit(chunk1, chunk2);
}
Fixed Size Padding + Compression Family
If the inputs are not padded, the compression function alone is not sufficient to produce a correct SHA-256 output - regardless of their size. To pad to correct size, the library provides interfaces that operate on inputs of particular sizes, applying both padding and compression:
256bitPadded.zok: 256-bit inputs (32 bytes)512bitPadded.zok: 512-bit inputs (64 bytes)1024bitPadded.zok: 1024-bit inputs (128 bytes)
Fixed-size padding interfaces leverage knowledge of the input size to optimize the padding process.
Variable Size Padding + Compression
When the size of your input does not match any of the fixed-size interfaces,
sha256Padded.zok
enables processing inputs of any size:
// Example: SHA-256 for variable size padding
import "hashes/sha256/sha256Padded" as varSizeSha256;
def main(u8[100] input) -> u32[8] {
// Pad then compress
return varSizeSha256(input);
}
Note that unlike the other variants which take arrays of u32 as input,
input to sha256Padded is an array of bytes.
3. Examples
Example 1: Basic Use
The goal of this example is to demonstrate the logically equivalent ZoKrates
version of a basic python hashing code.
The following python snippet creates a SHA-256 digest for the string Hello
World and compares it to a known hash:
import hashlib
preimage = b"Hello World"
digest = hashlib.sha256(preimage).hexdigest()
assert digest == "a591a6d40bf420404a011733cfb7b190d62c65bf0bcda32b57b277d9ad9f146e"
Note that python’s hashlib.sha256 performs both padding and compression.
The following ZoKrates code replicates the same SHA-256 digest generation. Because there is no ZoKrate’s interface for hashing fixed-size 11-byte inputs, we are going to use the variable size padding interface:
import "hashes/sha256/sha256Padded" as sha256;
def main() {
// Byte representation of the string "Hello World"
u8[11] preimage = [0x48, 0x65, 0x6c, 0x6c, 0x6f, 0x20, 0x57, 0x6f, 0x72, 0x6c, 0x64];
u32[8] digest = sha256(preimage);
u32[8] expected = [ 0xa591a6d4,
0x0bf42040,
0x4a011733,
0xcfb7b190,
0xd62c65bf,
0x0bcda32b,
0x57b277d9,
0xad9f146e
];
assert(digest == expected);
}
Example 2: Knowledge of Proof of Work of a Bitcoin Block
In this example we show to prove knowledge of the solution to the proof of work puzzle of a bitcoin block.
A bitcoin block header contains the following information:
version: 4 bytes
previous block hash: 32 bytes
merkle root hash: 32 bytes
time: 4 bytes
nBits: 4 bytes
nonce: 4 bytes
Altogether, these fields constitute a constant size 80-byte header. To mine a block, miners are required to find a correct value for the nonce field, such that double hashing of the entire 80-byte block header (including that nonce) produces a correct solution to the proof of work puzzle. Lets assume you found the nonce and want to prove to someone that you know it without disclosing it (otherwise they could claim the block reward without the mining work). The ZoKrates code then looks as follows:
import "hashes/sha256/sha256Padded" as varSizeSha256;
import "hashes/sha256/256bitPadded" as fixedSizeSha256;
def main(private u8[80] serialized_block_header, u32[8] block_hash) {
u32[8] hash1 = varSizeSha256(serialized_block_header);
u32[8] hash2 = fixedSizeSha256(hash1);
assert(hash2 == block_hash);
}
The program takes a private input of 80 bytes which is the serialized block
header including the nonce, and a 256 bit hash output.
To produce the first hash, we use the variable size padding function from
sha256Padded as there is no available interface matching exactly 80 bytes
input size.
This always produces a 32-byte output (512 bits), and we
have an interface for processing inputs with exactly that number of bits:
256bitPadded.
Finally the hash output is compared against the given
block_hash.
Next we demonstrate usage with the aid of a small python script.
Say you have figured the nonce for block #505400. The following python program complements the above ZoKrates code by producing proper ZoKrates inputs from the information of a block header.
import struct
from hashlib import sha256
def serialize_header(version: str, prevblock_hash: str, merkle_root: str, time: int, bits: int, nonce: int):
return bytes.fromhex(version)[::-1] + \
bytes.fromhex(prevblock_hash)[::-1] + \
bytes.fromhex(merkle_root)[::-1] + \
time.to_bytes(4, byteorder='little') + \
bits.to_bytes(4, byteorder='little') + \
nonce.to_bytes(4, byteorder='little')
# values (from https://www.blockchain.com/explorer/blocks/btc/505400)
serialized_block_header = serialize_header(
version='20000000',
prevblock_hash='00000000000000000022a664b3ff1e4f85140eddeebd0efcbe6a543d45c4135f',
merkle_root='a3defcaa713d267eacab786c4cc9c0df895d8ac02066df6c84c7aec437ae17ae',
time=1516561306,
bits=394155916,
nonce=2816816696
)
# double hashing
hash1 = sha256(serialized_block_header).digest()
hash2 = sha256(hash1).digest()
# encode block_data as 80 unsigned byte values
input_encoded = struct.unpack('80B', serialized_block_header)
# encode block_hash as 8 32bit integers
output_encoded = struct.unpack('>8I', hash2)
# format input and output as ZoKrates arguments
args = " ".join(map(str, input_encoded + output_encoded))
print(args)
Putting everything together we can generate proofs as follows:
zokrates compile -i pow.zok
zokrates setup
python3 pow.py | zokrates compute-witness --stdin
zokrates generate-proof
zokrates verify
Performing verification...
PASSED
4. Summary and Conclusion
We have looked into the various interfaces ZoKrates provides for computing SHA-256. The compression only family expect inputs to be already padded to SHA-256’s block size, the fixed-size padding family pads inputs of particular sizes, and finally the variable size padding enables padding inputs of any size. The example showed how hashing in ZoKrates compares to hashing in python, and finally, the bitcoin proof of work example showed how to use ZoKrates to prove knowledge of the solution to a block puzzle.
Which SHA-256 interface should I use?
For maximum efficiency, you should carry out all preprocessing steps like padding outside of ZoKrates (e.g., using python), and use ZoKrates for compression only (i.e, the actual hashing). Note, however, that an incorrect padding could result in both correctness and security problems. If you are worried of not doing it correctly, then use the fixed size padding family if your input size matches one of them, or the variable size padding for maximum flexibility.
For more information, check out the ZoKrates Documentation and ZoKrates test cases.
Leave a comment